Introduction
Most GNN models (e.g., GraphSAGE) are trained based on static graphs. There also exists many business scenarios where the graph structure and features change dynamically. Such dynamicity should be captured by the processes of model training and inference. Temporal GNN models (e.g., EvolveGCN, TGAT and TGN) are proposed for training on dynamic graphs. To support online inference on dynamic graphs, we propose Dynamic Graph Service (DGS) to facilitate real-time sampling on dynamic graphs. The sampled subgraph can be fed into the serving modules (e.g., TF serving) to obtain the inference results.
Note that, although the traditional static GNN models cannot reflect the temporal information, DGS can be used to integrate the real-time changes in graph structure and features into the inferenced representations. We provide an end-to-end tutorial illustrating an integrated solution for training and inference.
Architecture
To fulfill the stringent latency requirement of online inference, instead of using a dynamic graph store and query engine, DGS samples the update streams of dynamic graphs in real-time according to the pre-configured sample query, and only caches the sampled graph updates to serve the inference requests. In a single-node environment (64 cores, 256G RAM), DGS can complete a 2-hop sampling query within 20ms (P99 latency), achieve a QPS of 20,000 and at the same time supports graph updates with a throughput of 110 MB/S. These performance metrics can scale out linearly in the distributed environment. The architecture of DGS is presented as follows:
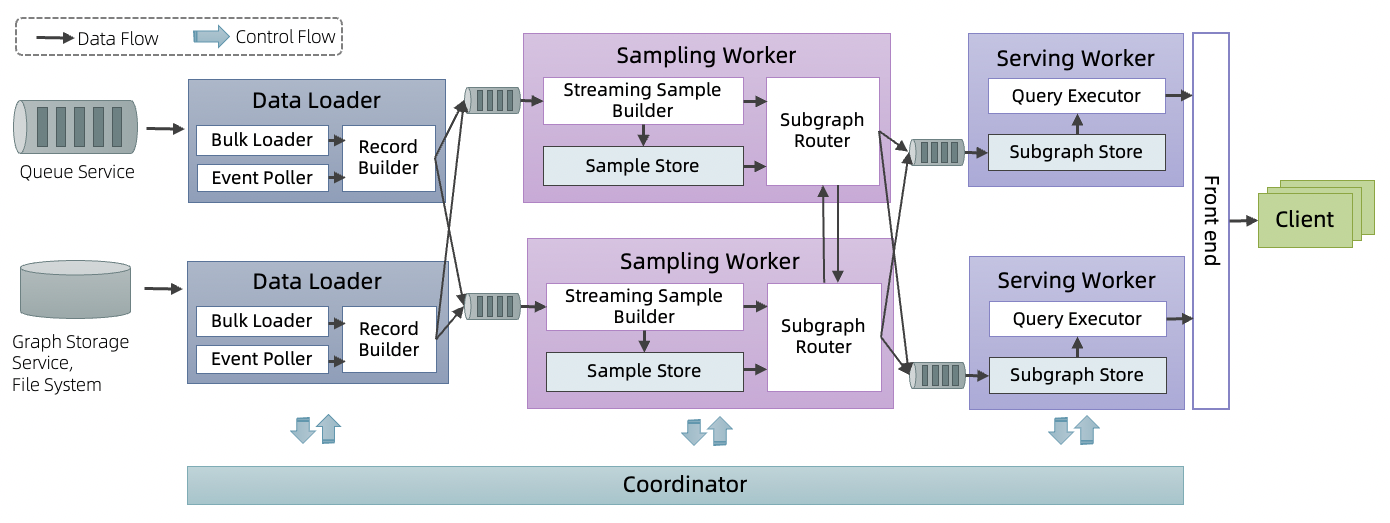
DGS consists of three subservices, which are Data Loader, Sampling Worker and Serving Worker. Data loader acts as the interface between the sources of graph updates, it shards the graph updates according to a specified partitioning function and routes the updates to the corresponding sampling workers. Each sampling worker performs multiple 1-hop sampling operations (decomposed from the n-hop sampling query), and dispatches the sampled updates to serving workers. The sample dispatching follows the principle that, the n-hop sample results of a specific vertex must be dispatched to the same serving worker. The inference requests are served by the serving workers. On receiving an inference request, the serving worker reconstructs the complete sample results from its local cache. This way, the execution of a sample request is transformed to multiple local memory lookups. These subservices are connected via fault-tolerant queue services, which are also used to support the fault tolerance mechanism of DGS. The graph updates flow through the subservices as follows:
(1) Data Loader: Ingest graph updates from the data sources via bulk loading or streaming. According to the types of the updates, the Record Builder in data loader will build a VertexUpdateRecord or EdgeUpdateRecord. Records are pushed into queues according to the specified partitioning policy.
(2) Sampling Worker: According to the installed query, the records streamed into each sampling worker are sampled. The samples are written into the Sample Store. The dependency information of the samples are maintained in the Subscription Table. The Subgraph Router dispatches samples to the output queues according to the dependency information in Subscription Table.
(3) Serving Worker: Pull data (sampled updates) from the input queue and write it to the local SubGraph Store. On receiving a sample request from the client, it reads the cached samples from the local store, reorganizes the samples and returns the sampled subgraph to the client.