范式与流程
图学习算法,尤其是图神经网络GNNs, 和一般的DNN模型最大的区别是样本间存在关系或者依赖。这种数据间依赖关系导致GNNs模型很难直接使用TensorFlow或者PyTorch这样的深度学习引擎来开发。第一是因为图数据和一般的图像、文本数据不同,无法直接使用或者无法高效使用TensorFlow和PyTorch提供的数据处理功能,尤其是对大规模异构图;第二是因为GNN是基于图结构数据进行计算,计算路径是图中的点和边,直接基于TensorFlow或者PyTorch原始的API构建模型并不是很容易。为了解决这些问题,我们从过去的实际业务经验出发,总结之前版本的缺点,实现了一套简洁的GNNs算法开发的范式和流程。我们希望通过这套范式,简化GNNs算法的开发,方便算法开发者快速构建适合自己业务场景的GNNs算法。
模型范式
大部分GNNs算法遵循消息传递或者邻居聚合的计算范式,有些框架和paper将消息传递过程又具体分为aggregate, update等阶段,但是实际上不同GNNs算法所需要的计算过程并不完全一致,我们不再提供实现细节的抽象,而是统一把消息传递/邻居聚合过程抽象成神经网络里的一个layer来实现,具体地,对于目前常见的图卷积神经网络,我们实现了若干conv层来表示消息传递过程。
在实际业务应用中,图的规模比较大,图的节点和边上的特征也比较复杂(可能同时有离散和连续特征),因此无法直接在原始图上进行消息传递/邻居聚合。一种可行和高效的做法是基于采样的思路,先从图中采样出一个子图,然后基于子图进行计算。采样出子图后,对该子图的点、边特征进行预处理,统一处理为向量,就可以基于该子图进行高效的消息传递的计算。
总结来说,我们将GNNs的范式归结为:子图采样,特征预处理,消息传递3个阶段。
子图采样:通过GraphLearn提供的GSL采样得到子图,GSL提供图数据遍历,邻居采样,负采样等功能。
特征预处理:将点、边的原始特征进行预处理,比如对离散特征进行向量化(embedding lookup)。
消息传递:通过图的拓扑关系进行特征的聚合和更新。
根据子图采样里邻居采样算子的区别和消息传递里NN算子的区别,我们将子图组织为EgoGraph或SubGraph的格式。EgoGraph由中心对象ego和它的fixed-size的邻居组成,是一种dense的组织格式,基于EgoGraph的conv层的实现也是基于一些dense的NN算子,我们0.4及之前的版本都是基于EgoGraph来建模。SubGraph是一种更加通用的子图组织格式,由点、边的特征和edge index(由边的行index和列index组成的二维数组)组成,一般使用full neighbor sampler产生的sparse的结果会组织成SubGraph的格式,相应地,基于SubGraph的conv层一般使用sparse的NN算子。目前SubGraph还是experimental,边特征和异构图暂时没有支持。EgoGraph和SubGraph的示例如下图。

EgoGraph指Ego(中心节点)和k-hop Neighbors组成的一个子图;SubGraph是指一个广义的子图的,由nodes, edges和edge_index表示
接下来,我们介绍基于EgoGraph和基于SubGraph两种不同的计算范式。
基于EgoGraph的node-centric aggregation
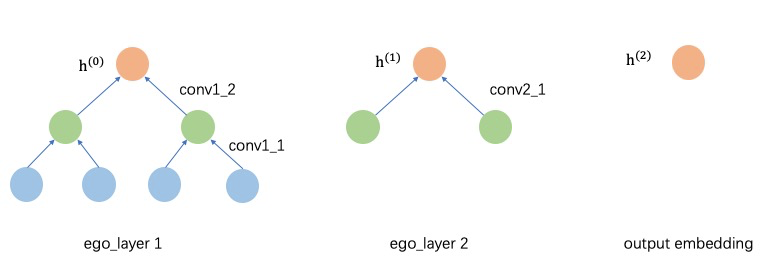
EgoGraph由ego和邻居构成,消息聚合路径通过ego和邻居间的潜在关系确定,k跳邻居只需要聚合k+1跳邻居的信息,整个消息传递过程是沿着邻居到自身的有向的meta-path进行。这种方式下,采样的邻居跳数和神经网络的层数需要完全一致。下图展示了一个2跳邻居的GNNs模型的计算过程。原始节点的向量记为h(0); 第一层前向过程需要将2跳邻居聚合到1跳邻居上,1跳邻居聚合到自身,不同跳邻居的类型可能不同,因此第一层需要两个不同的conv层(对于同构图,这两个conv层相同),第一层后节点的特征更新为h(1),作为第二层的输入;第二层时,需要聚合1跳邻居的h(1) 来更新ego节点特征,最终的输出的节点特征h(2)为最终的输出ego节点的embedding。
基于SubGraph的graph message passing
和EgoGraph不同,SubGraph里包含有图的拓扑关系的edge_index,因此消息传播路径(前向计算路径)可以通过edge_index直接确定,conv层的实现可以直接通过edge_index和nodes/edges数据进行。另外,SubGraph和PyG里的Data完全兼容,因此可以复用PyG的模型部分。
EgoGraph和SubGraph的对比
| EgoGraph | SubGraph | |
|---|---|---|
| 数据组成 | 自身节点和k-hop邻居节点 | 节点和edge_index |
| 拓扑关系 | 只有k-hop邻居的树状拓扑关系 | 子图拓扑关系 |
| 支持的采样算子 | fix-sized neighbor sampler | full neighbor sampler |
| 编程范式 | node-centric aggregation(GraphSAGE like) | graph message passing(like DGL/PyG) |
| NN算子 | dense | sparse(segment_sum/mean...) |
| 计算路径 | 邻居节点到中心节点 | source节点到destination节点 |
| 异构图支持 | 支持 | 支持(since v1.1.0) |
| PyTorch支持 | 未实现 | 兼容PyG,对应PyG里的Data |
| 已经实现的算法 | 0.4模型都基于EgoGraph实现。 | |
| GraphSAGE,二部图GraphSAGE/GAT等 | GCN, GAT, GraphSAGE, SEAL等 |
注:EgoGraph本身表示一个batch的点和邻居;SubGraph只表示一个子图,batch的子图用BatchGraph表示。
在实际使用时,具体用EgoGraph还是SubGraph可以根据上面的对比进行选择,目前SubGraph还是实验性质的,建议优先使用EgoGraph。对于PyTorch,目前模型层直接复用pyG,我们实现了Dataset和PyGDataLoader来将GSL数据转成pyG的Data和Batch格式,pyG的Data相当于我们的SubGraph, Batch相当于BatchGraph。
开发流程
一个GNN训练/预测任务,通常包含以下步骤。
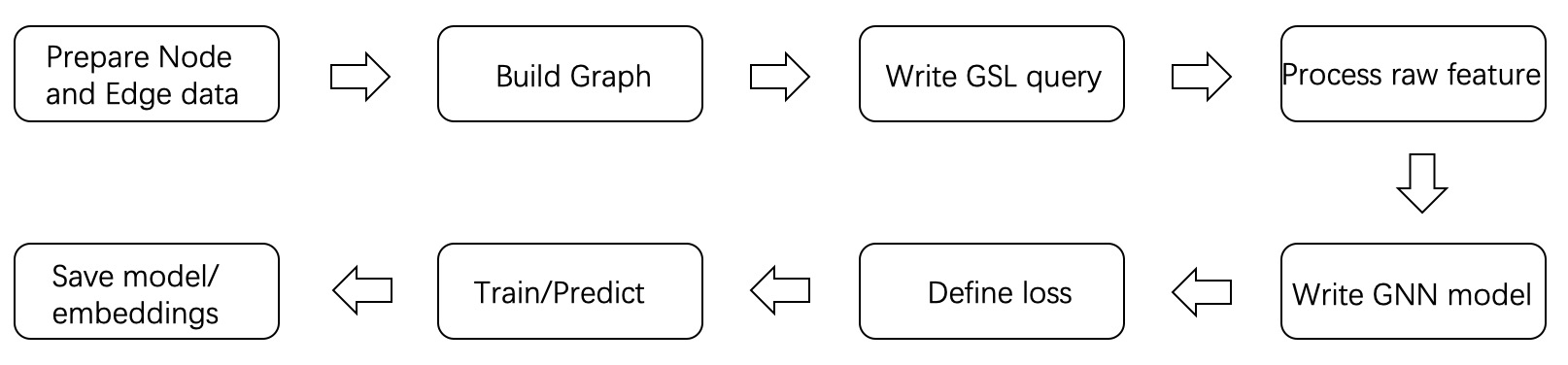
首先基于业务准备图数据。图数据以顶点表和边表的形式存在,具体格式参考“图操作接口->数据源”一节。通常情况下,业务会涉及多种类型的顶点和边,使用GraphLearn提供的接口逐一添加即可。顶点和边的数据源是独立的,在添加到GraphLearn后,后台引擎会完成异构图的构建。图数据的构建是非常重要的一个环节,它决定了算法学习的上限,因此如何生成合理的边数据,如何选择合适的特征都需要和业务目标一致。欢迎大家可以在GraphLearn用户群积极分享和讨论自己的构图经验。
图构建完成后,需要从图中采样获取训练的样本,建议使用GSL来构建样本query, 这样可以使用GraphLearn的异步和多线程缓存的采样查询功能,高效地生成训练样本流。
GSL的输出为Numpy格式,而基于TensorFlow或PyTorch的模型需要tensor格式的数据,因此首先需要进行数据格式的转换,另外原始图数据的特征可能比较复杂,无法直接接入模型训练,例如点特征“id=123456,age=28,city=北京”等明文,需要经过embedding lookup处理成连续特征。不同特征的含义是不同的,向量化的空间和维度都不一样,因此需要在添加顶点或边数据源时描述清楚每个特征的类型、取值空间、向量化后的维度。基于以上信息,GraphLearn提供了便捷的接口把原始数据转换成向量格式,再进一步参与到模型层的计算。
在GNN模型构建方面,GraphLearn封装了EgoGraph based的层和模型,以及SubGraph based的层和模型,选择适合自己的模型范式后即可使用这些层搭建一个GNNs模型。GNNs模型以EgoGraph或者BatchGraph(mini batch的SubGraph)作为输入,输出节点的embedding。
得到顶点的embedding后,再结合业务需要设计损失函数,常见场景可归为顶点分类、连接预测两大类。以连接预测为例,需要“源顶点的embedding,目的顶点的embedding,负采样目标顶点的embedding”作为输入,输出loss,再通过训练器不断迭代优化该loss。GraphLearn封装了一些常见的loss函数,具体可以参考“常见loss”一节。
GraphLearn的算法侧整体框架如下图所示,
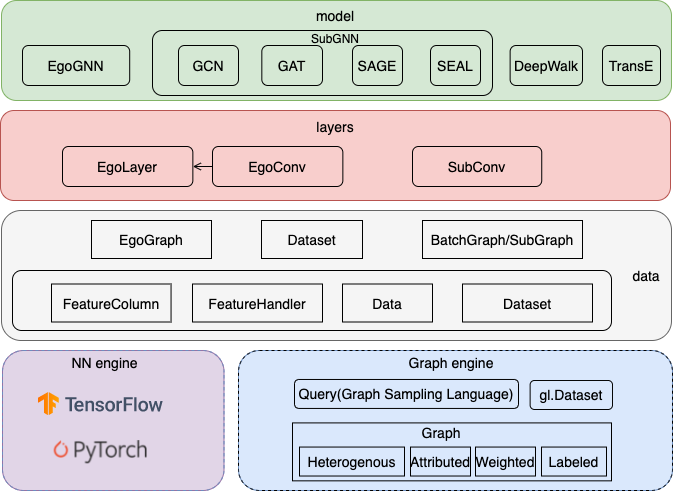
框架底层是一个基于分布式内存的图查询/计算引擎,提供异构,多属性,带权重,有标签,有向/无向图的点、边遍历、邻居采样、负采样、属性查询等功能,同时支持TensorFlow1.12.0和PyTorch1.8.1 backend。从下往上依次是数据层data, 模型层layers和model, 最后提供了若干基本的和常用的examples。具体各个模块的细节参考不同backend(tensorflow或者pytorch)下的“数据层”和“模型层”章节。
我们致力于打造面向算法开发者的简洁、灵活、丰富、高效的算法框架,同时关注算法创新和业务落地,推动图学习在推荐、安全等多个场景的实际落地。后续我们也会逐步针对这些场景,打造高效易用的算法库,欢迎大家积极讨论,如果我们的工作对你有所帮助,请告知我们,也欢迎贡献代码。